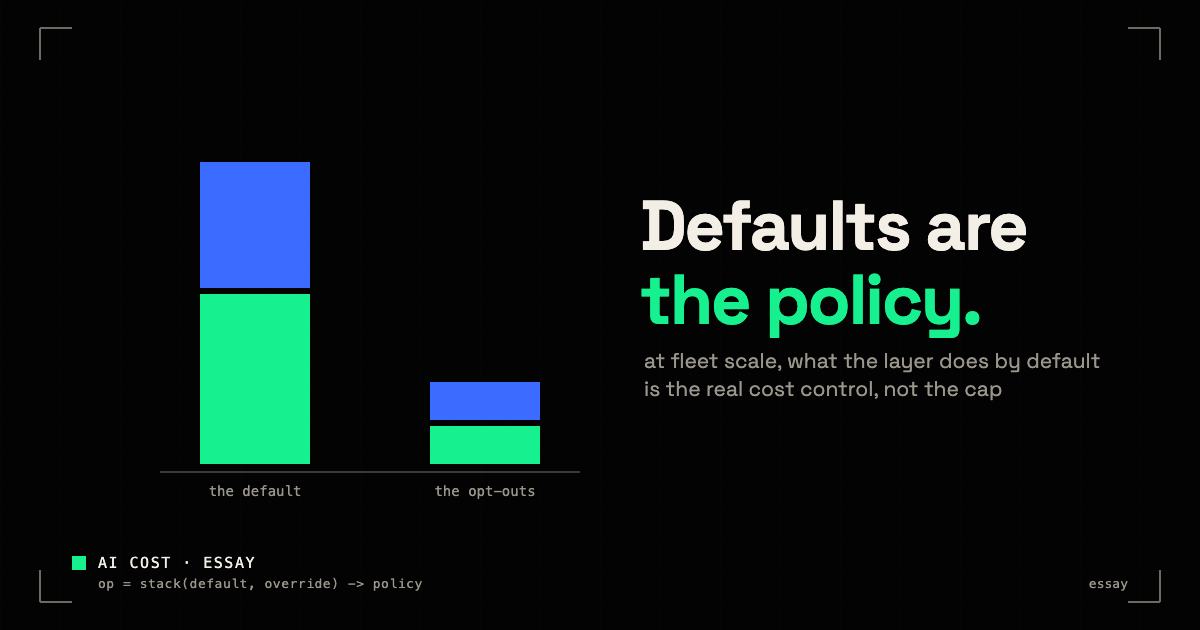
Defaults are the policy
AI token cost at fleet scale isn't controlled by caps or willpower. It's set by what your model layer does by default, and who understands the work.
ai cost agents platform
Filtering by
AI token cost at fleet scale isn't controlled by caps or willpower. It's set by what your model layer does by default, and who understands the work.

Months of conversations with executives and architects, the exposure feeling of building systems that have never been built before, and why resistance is the signal to keep climbing.
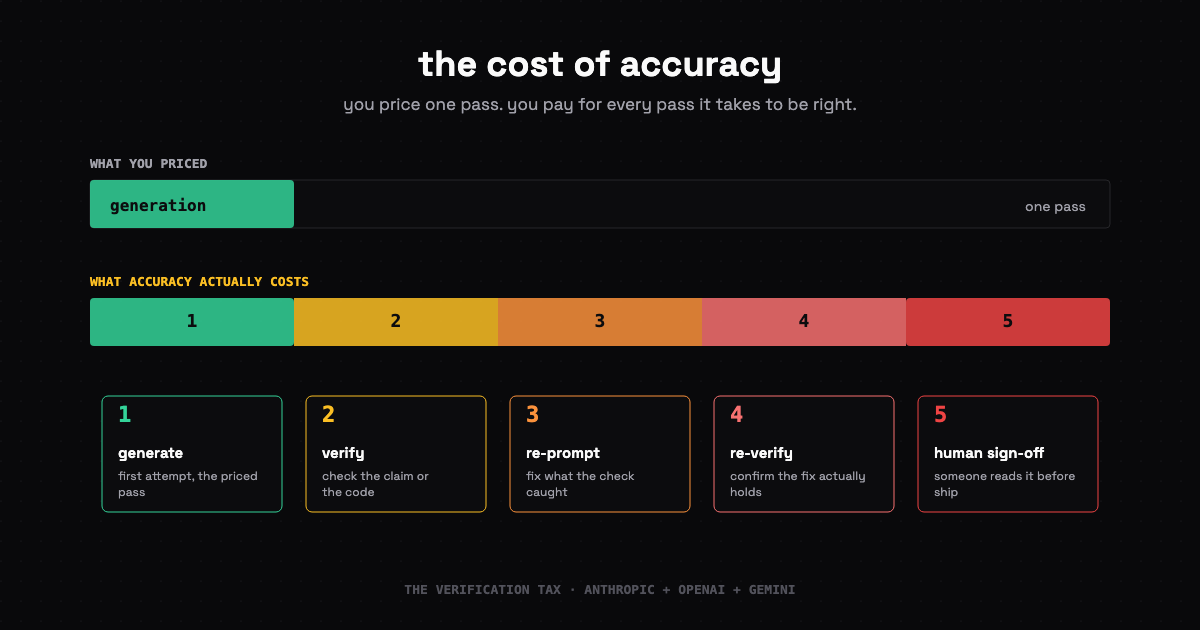
You don't buy answers from a frontier model, you buy passes. Most real tasks take more than one, and the verification passes are where the budget actually goes.

The four-practice discipline I built after eighteen months of heavy AI use. Without deliberate friction, AI compounds capability and dependence.

Adaptive thinking and a literalness shift turned the Opus 4.7 prompt into a multi-dimensional contract. Half your prompt library signs old terms.

The agentic loop is a while loop that checks stop_reason, executes tools, and returns results. It is 10 lines of code that depend on everything from posts 0-8.

Scaling an agentic loop to production means managing cost, context, and complexity. A roadmap: prompt caching, model routing, compaction, subagents, MCP.

Tool use lets Claude call functions you define. You ship schemas, the model picks when to call, your code runs the operations. Prerequisite for agents.

Structured outputs guarantee JSON schema conformance at the API level, which removes an entire category of parsing and validation code from your pipeline.
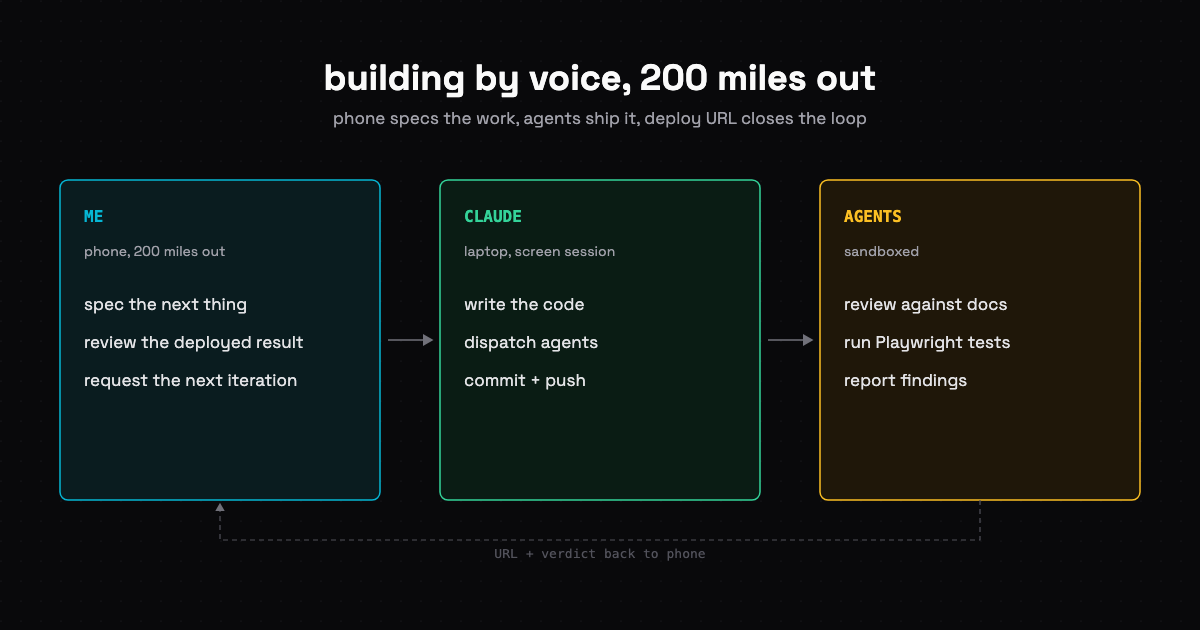
Built a word-by-word audio sync feature for a blog post without touching my laptop. Voice on the phone, agents on the laptop, every change shipped to prod.

Extended thinking gives Claude a reasoning scratchpad before responding. It costs output tokens but measurably improves accuracy on hard problems.

Frontier LLMs are not deterministic, even at temperature=0. Same prompt, five different answers. Why it compounds when you stack LLMs, and how to recover.

As models get smarter, the value shifts from crafting prompts to designing the system around them. Where the prompt ends and the harness begins is the question.

A 16-hour Claude Code session shipped a long-form post, three SVG diagrams, a CI script, and four legacy fixes from a seven-word instruction.

Long context did not kill RAG for incident response. Per-section indexing in pgvector, hybrid .docx extraction, an iterative Mastra agent loop on Bedrock.
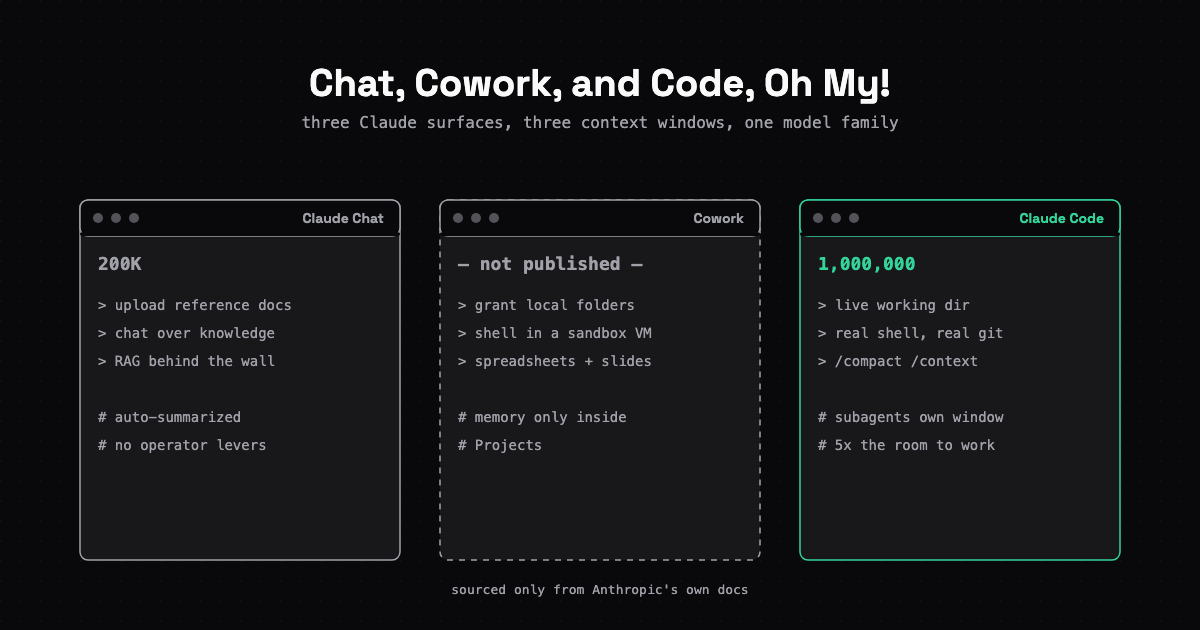
Three Claude surfaces, three context windows, three different ways of knowing about your files. Confirmed only from Anthropic's own documentation.

Every Claude API call is stateless. You send roles, messages, and the full conversation history each time. Here is how that structure works.

A one-command Claude Code plugin renders three progress bars: context fill, 5-hour session burn, 7-day weekly quota. No ccusage required on CC v2.1.x+.

Six phases to ship a Claude skill like software: behavioral eval, packaging, review, CI, install verification, governance. Each catches a different bug.

Part 3 of 3. Four structural fix patterns that move an AI reviewer from ignorable to trustworthy, plus the meta problem of using AI to audit AI.
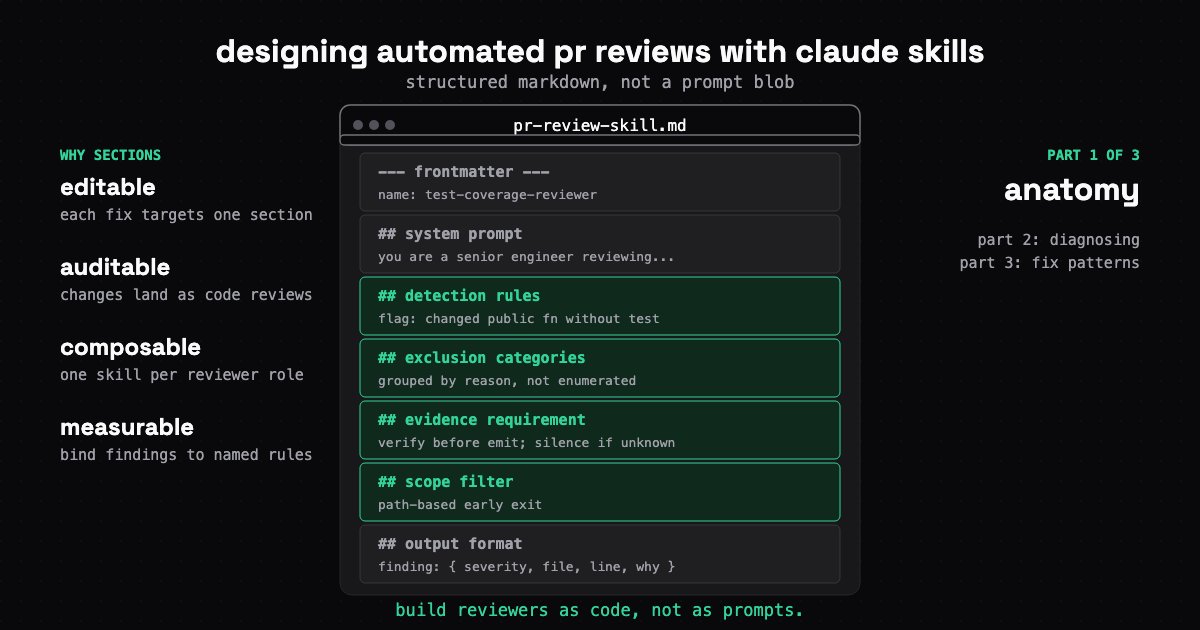
Part 1 of 3. Building a PR reviewer as structured Claude skills: anatomy of a review skill, why markdown beats prompt blobs, what makes iteration possible.
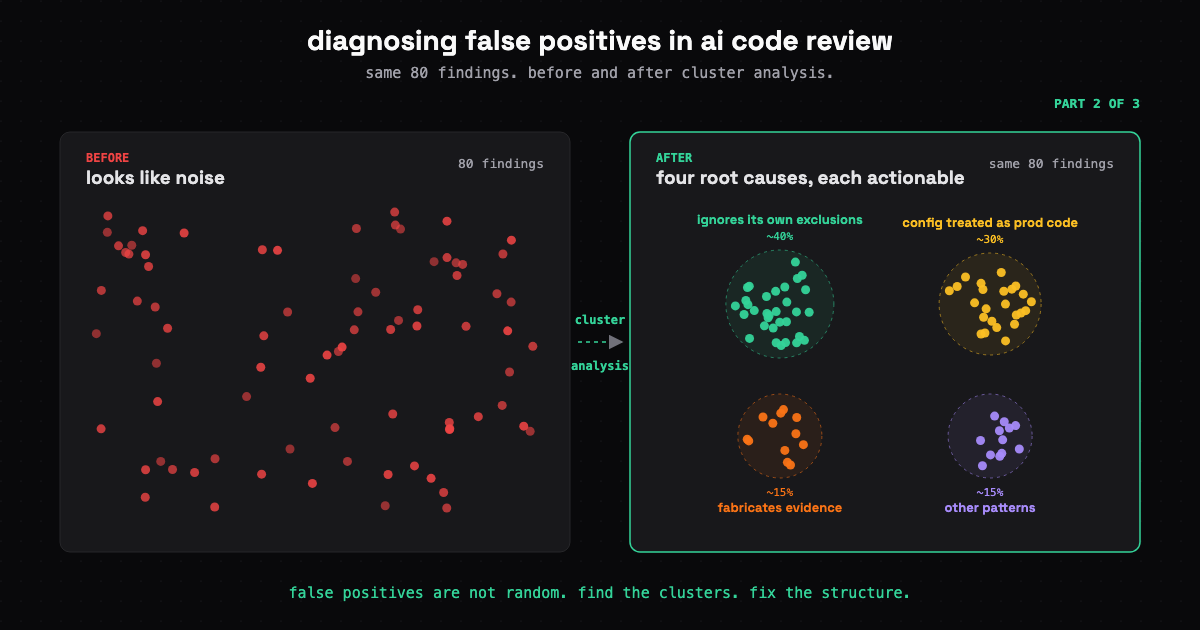
Part 2 of 3. The cry wolf failure mode, the trust threshold step function, and a four-step cluster analysis that surfaces root causes, not symptoms.

Your brain burns 20% of your body's energy. Creatine refills brain ATP 40x faster than any other pathway. What that means for devs at their keyboards.
Context windows are working memory, not storage. More tokens means more cost, more latency, and accuracy that degrades as context grows.

Large language models are prediction machines built on transformers. What they are, how developers use them, and where agent workflows fit in.

LLMs predict one token at a time from a probability distribution. Temperature, top-k, and top-p control that distribution, not creativity.

LLMs don't process words or characters. They process tokens, subword units that determine cost, speed, and context limits for everything you build.
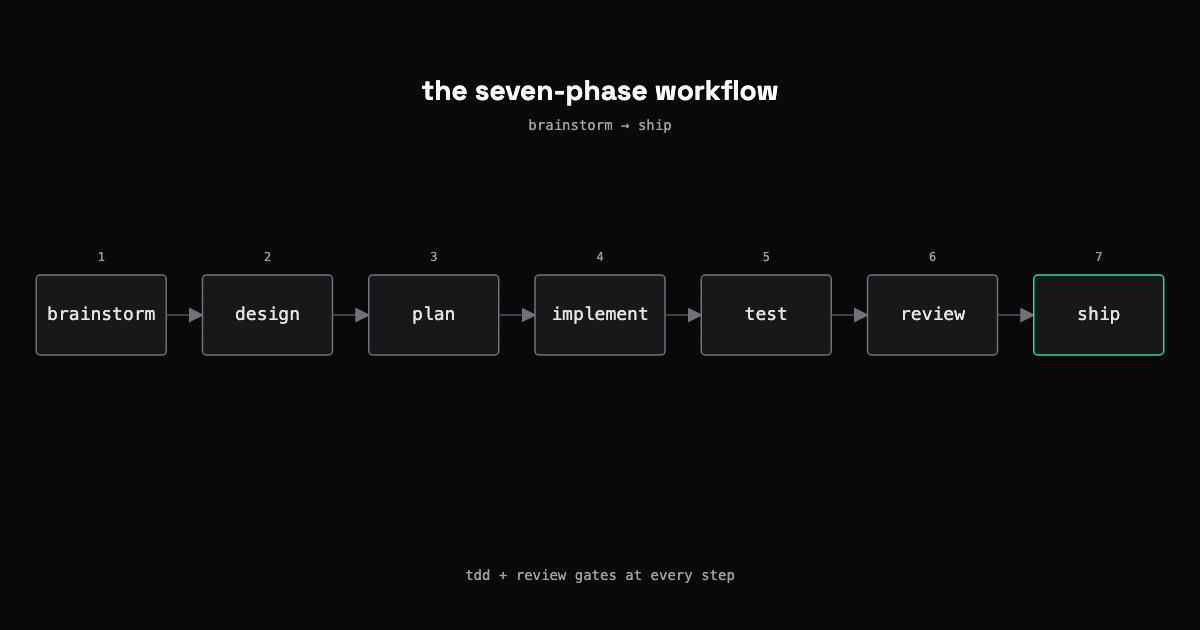
A structured Claude Code workflow that replaced plan-and-pray with repeatable, first-pass-clean features.
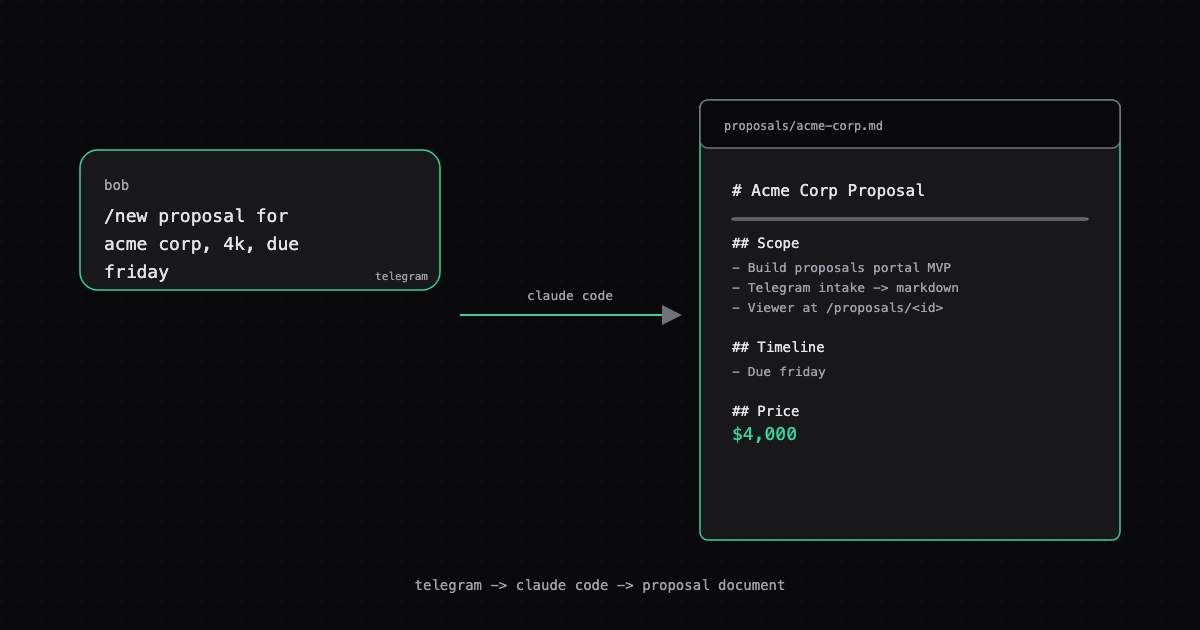
Magic link auth, progress tracking, and one-command publishing. Built with Claude Code, Astro, Cloudflare KV, and Resend from my phone.

I stood up a Mastra workflow from my phone via Telegram to monitor Cloudflare Workers. It caught bots crashing my media proxy on the very first run.

AI agents and channels integration make it possible to ship production code from anywhere: a summit, a grocery line, a dog walk. Why it works.
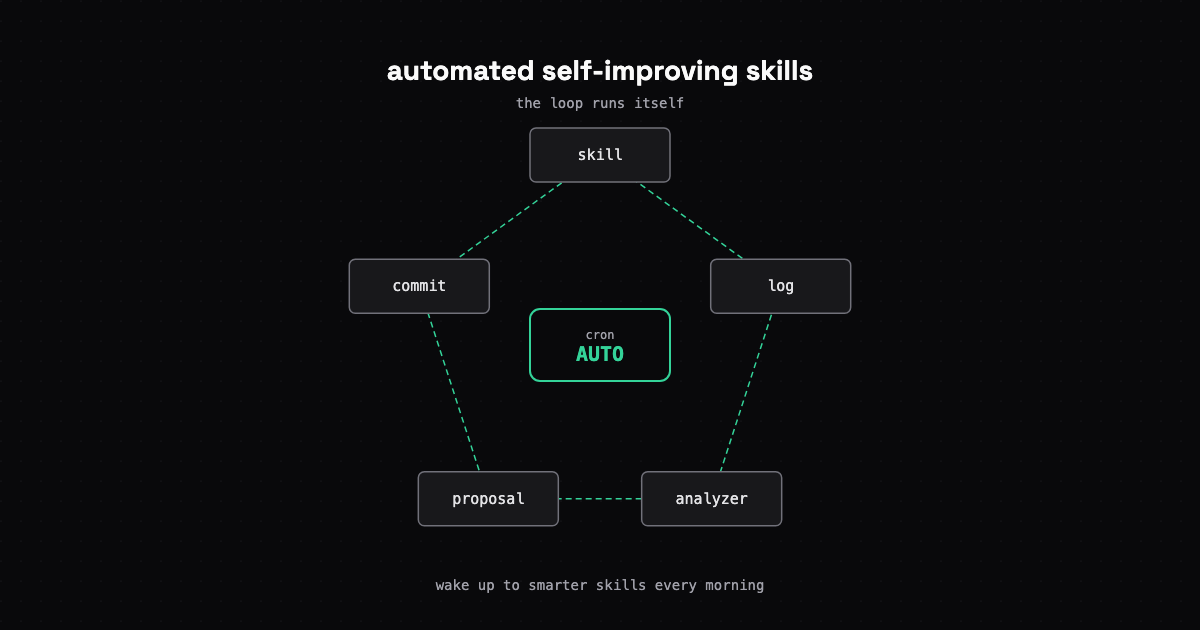
The self-improving Claude Code skills loop from Part 1 now runs itself. A SessionEnd hook and daily GitHub Action generate improvement PRs automatically.

A self-improving loop for Claude Code skills that observes failures, finds patterns, and proposes fixes. Skills that improve over time instead of degrading.

How I implemented LLM SEO across 3 sites with FAQ schema, entity linking, and 14 AI crawlers, plus an honest look at what actually works and what doesn't.
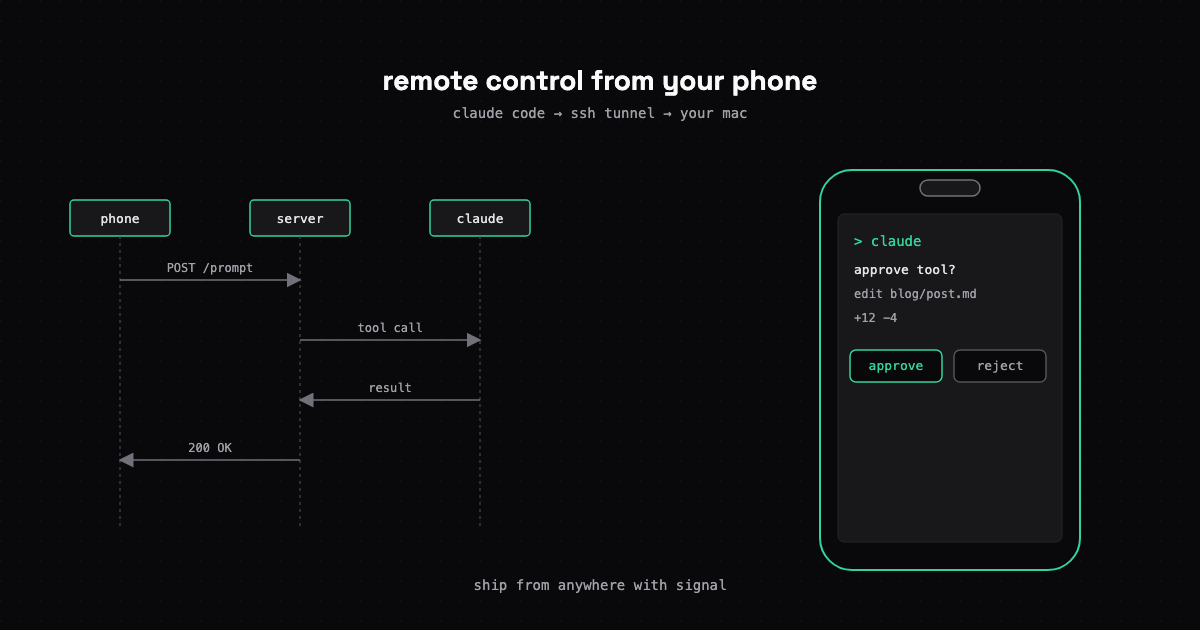
How I use Claude Code remote control with the iOS app to ship code from anywhere. No SSH tunneling, no exposed ports, just a Max subscription.

How I used Claude Code agents, context files, and slash commands to automate SEO for my Astro portfolio site: keywords, linking, and content audits.

Pixieset can't sell individual video clips. So I built my own storefront with Claude Code, Cloudflare R2, and Stripe, from my phone, on a Sunday morning.
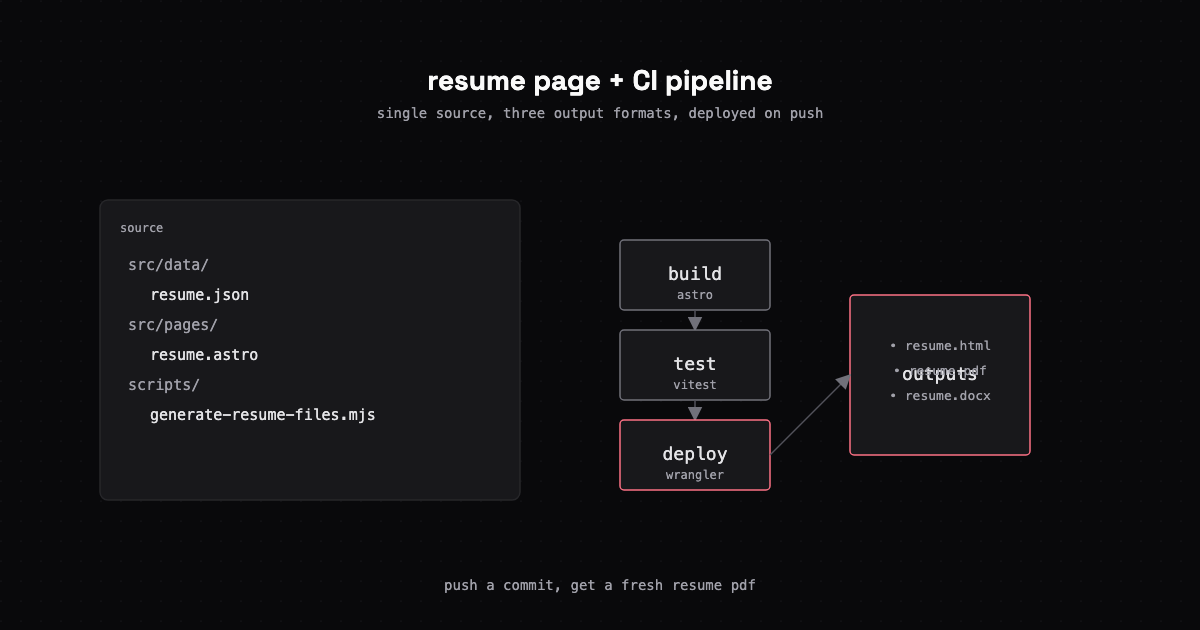
How I built a filterable tech resume with multiple export formats and set up a proper CI/CD pipeline with GitHub Actions and Dependabot.
How I went from 'I need to track Christmas gifts' to a fully deployed, PIN-protected wishlist app before my morning coffee got cold.
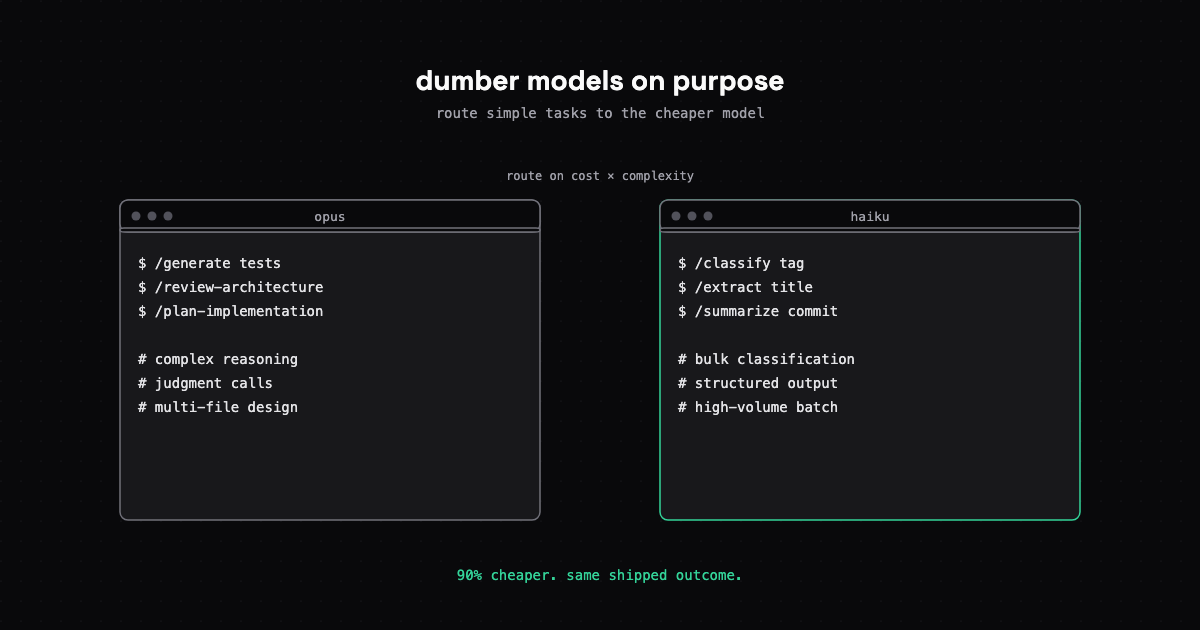
Why the most capable AI isn't always the right tool, and how friction in your workflow can lead to better architecture decisions.